Welcome to HAWKS’s documentation!¶
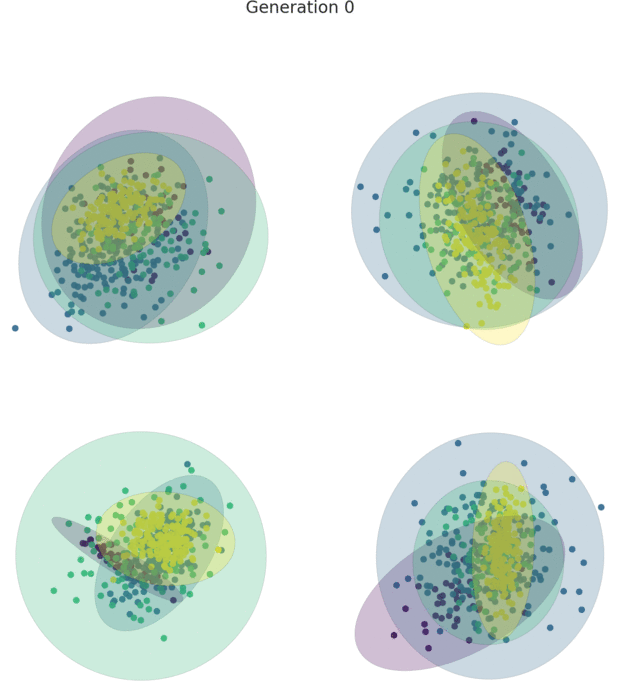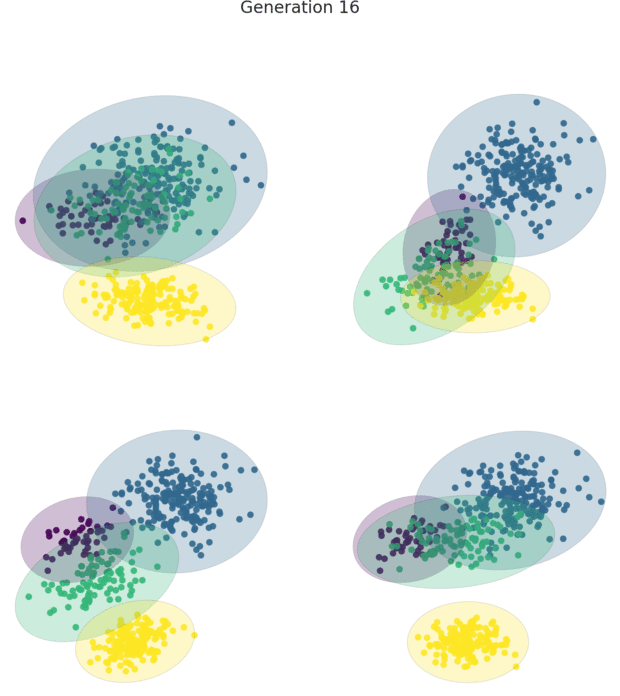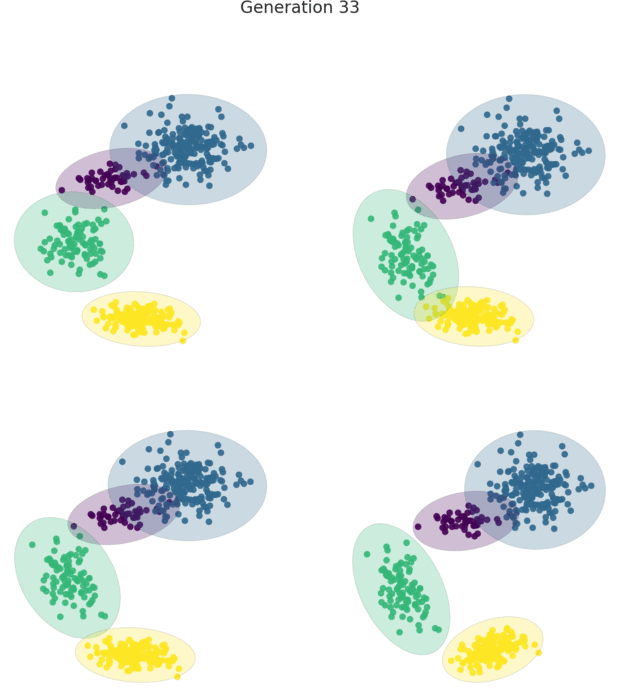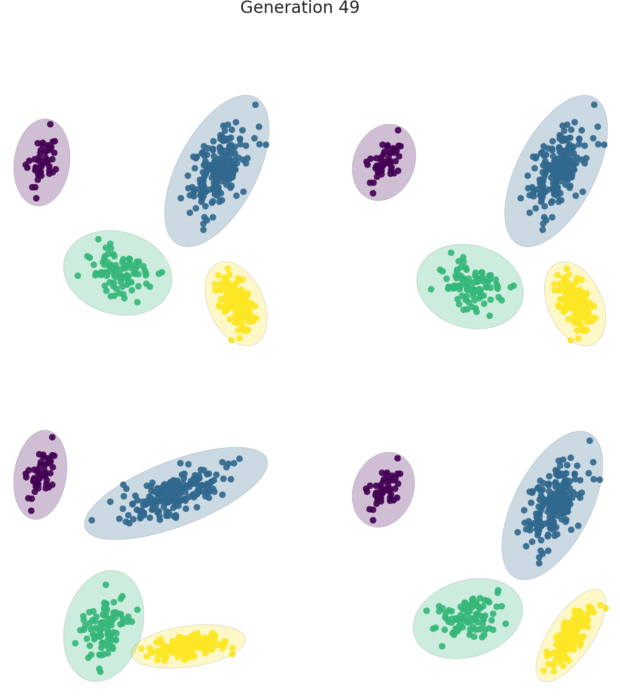
HAWKS is a tool for generating controllably difficult synthetic data, used primarily for clustering.
The associated repo for this documentation is associated with the following paper:
- Shand, C., Allmendinger, R., Handl, J., Webb, A., & Keane, J. (2019, July). Evolving controllably difficult datasets for clustering. In Proceedings of the Genetic and Evolutionary Computation Conference (pp. 463-471). https://doi.org/10.1145/3321707.3321761 (Nominated for best paper on the evolutionary machine learning track at GECCO‘19)
Related BibTeX info:
@inproceedings{shand2019evolving,
title={Evolving controllably difficult datasets for clustering},
author={Shand, Cameron and Allmendinger, Richard and Handl, Julia and Webb, Andrew and Keane, John},
booktitle={Proceedings of the Genetic and Evolutionary Computation Conference},
pages={463--471},
year={2019},
url={https://doi.org/10.1145/3321707.3321761}
}
The academic/technical details can be found there. What follows here is a practical guide to using HAWKS to generate synthetic data.
If you use HAWKS to generate data that forms part of a paper, please cite the paper above and link to the repo.
Quick Example¶
"""Single, simple HAWKS run, with KMeans applied to the best dataset
"""
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import adjusted_rand_score
import hawks
# Set the magic seed number
SEED_NUM = 42
# Set the seed number in the config
config = {
"hawks": {
"folder_name": "simple_example",
"seed_num": SEED_NUM
},
"dataset": {
"num_clusters": 5
},
"objectives": {
"silhouette": {
"target": 0.9
}
}
}
# Any missing parameters will take from hawks/defaults.json
generator = hawks.create_generator(config)
# Run the generator
generator.run()
# Let's plot the best individual found
generator.plot_best_indivs(show=True)
# Get the best dataset found and it's labels
datasets, label_sets = generator.get_best_dataset()
# Stored as a list for multiple runs
data, labels = datasets[0], label_sets[0]
# Run KMeans on the data
km = KMeans(
n_clusters=len(np.unique(labels)), random_state=SEED_NUM
).fit(data)
# Plot the output of KMeans
hawks.plotting.scatter_prediction(data, km.labels_)
# Get the Adjusted Rand Index for KMeans on the data
ari = adjusted_rand_score(labels, km.labels_)
print(f"ARI: {ari}")
Output:
ARI: 0.9984430580527084
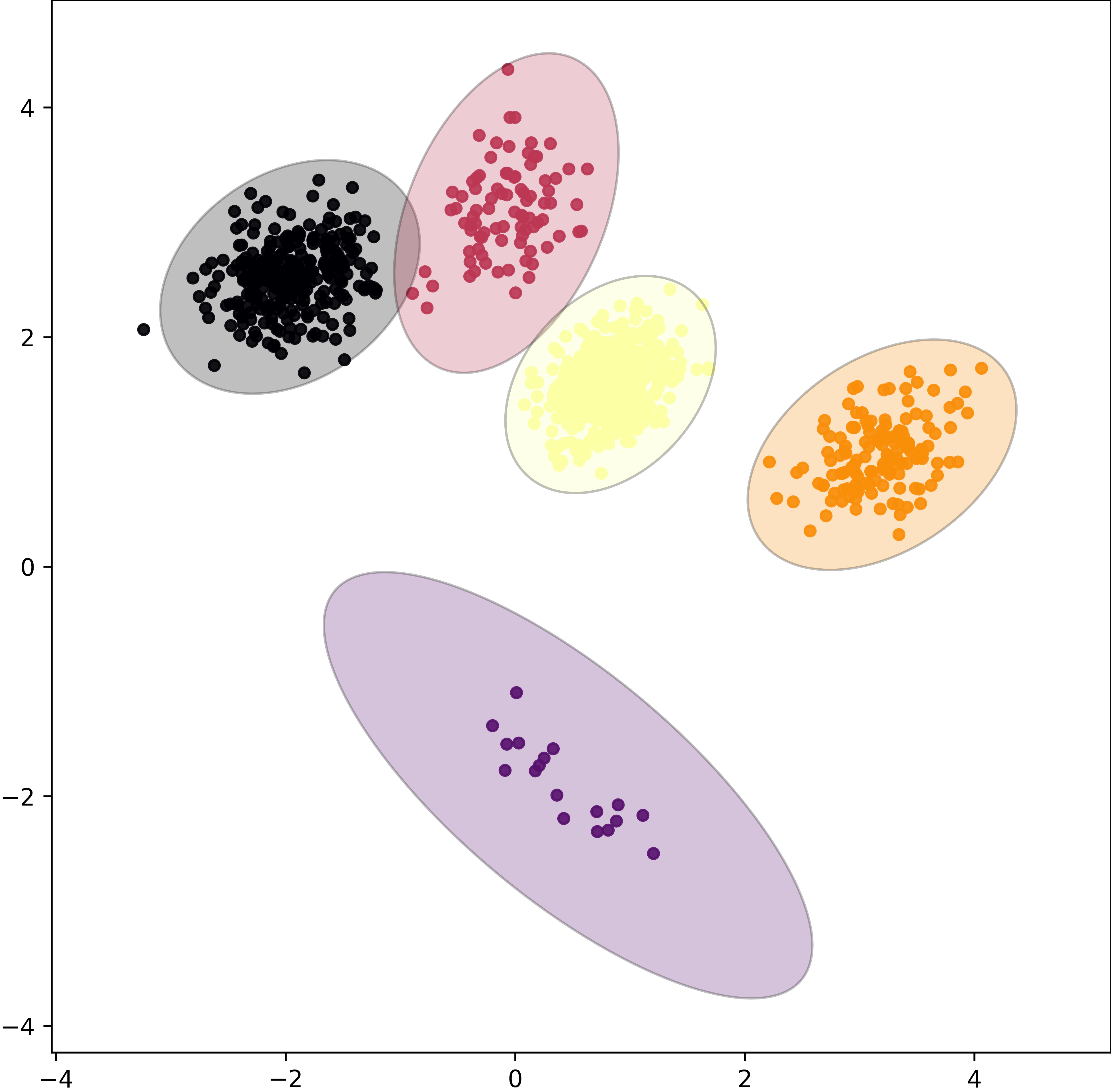
The dataset produced by the code above.
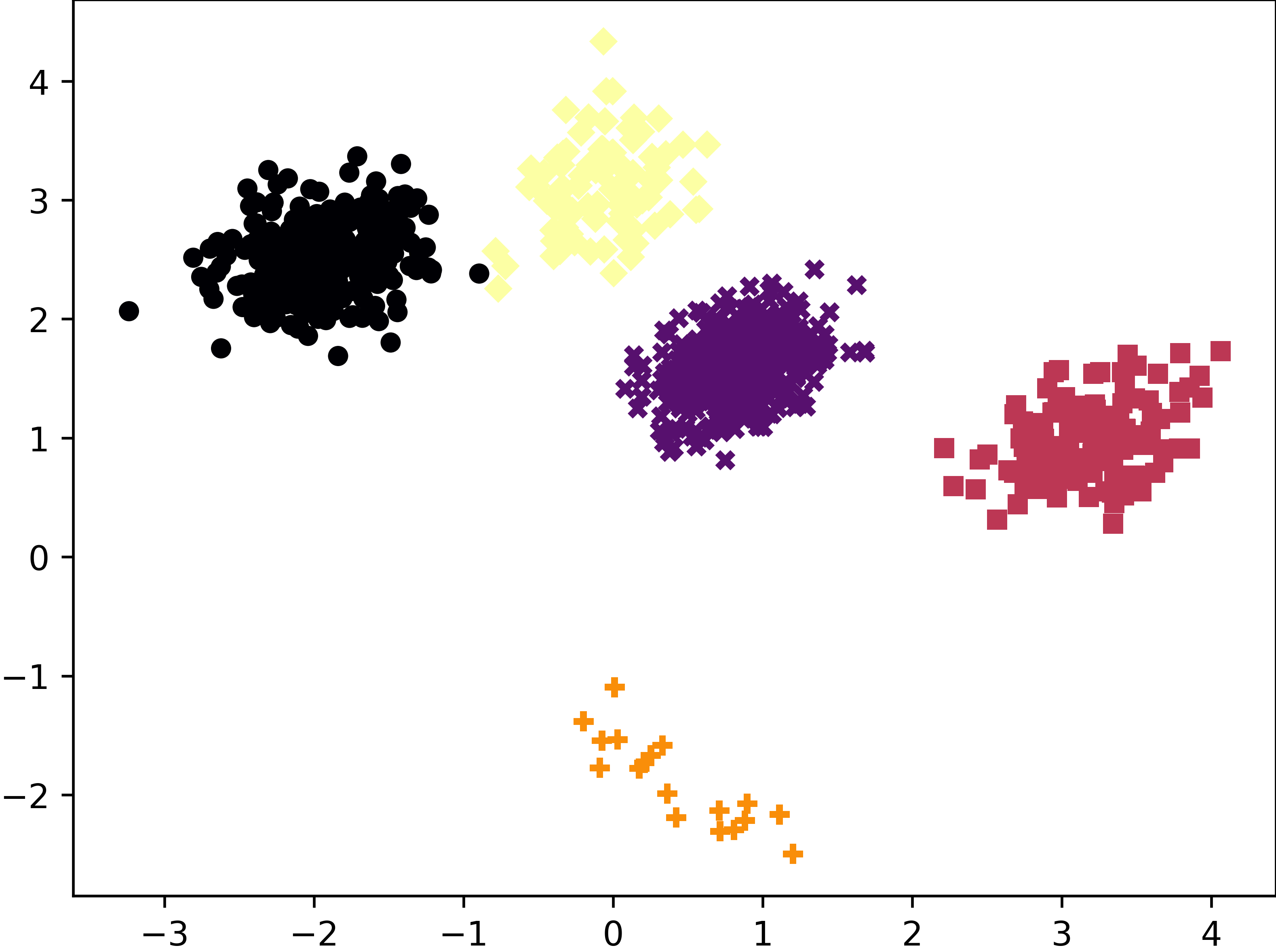
The predictions made by KMeans on the above dataset.